Publication 26 février 2026
L’IA générative en 2025 : état des lieux et perspectives

Description : Meta chief AI scientist Yann LeCun plans to exit and launch own start-up, Financial Times, 11 novembre 2025, https://www.ft.com/content/c586eb77-a16e-4363-ab0b-e877898b70de
Le mois de novembre 2025 a notamment été marqué par l’annonce du départ de Yann Le Cun de Meta. Cela, nous disait-on à l’époque, pour se concentrer sur les « World Model » plutôt que les LLM ; voie que suit Meta. LLM, World Model, Frontier Model, de quoi parle-t-on ?
Clément Bénesse :
Un LLM, c’est un « Large Language Model », soit un grand modèle de langage. C’est ce qu’on utilise au quotidien et dont ChatGPT est l’exemple le plus connu. L’une des grandes révolutions a été de comprendre qu’une des manières de construire une phrase revient à mettre des mots les uns après les autres. Le modèle fonctionne sur cette itération progressive, grâce à l’architecture Transformer qui permet de générer les mots séquentiellement. Depuis GPT-3, on pousse cette architecture au maximum, avec des améliorations. Mais, fondamentalement, on reste sur le même paradigme. Yann Le Cun, lui, n’y croit pas : il pense que cette architecture ne mènera pas à l’Artificial General Intelligence (AGI)», ; (ndlr : voir notre dernier rapport « Déployer une littératie en IA pour une société inclusive et émancipatrice », notamment page 61).
C’est là qu’intervient le prisme des World Model. ChatGPT excelle dans la mémorisation et le style « à la manière de », mais il peine à généraliser. Il a mémorisé une grande partie d’Internet et peut restituer l’information quand on le sollicite. Yann Le Cun veut « sortir de la caverne » platonicienne : se baser non pas sur la compréhension d’Internet (via des mots), mais sur celle du monde réel, notamment via l’analyse de vidéos.
On a pu constater ce manque de compréhension avec des tests simples. Essayez de demander à une IA de générer l’image d’une montre qui n’affiche pas 10h10 ! C’est compliqué, car les IA sont entraînées presque exclusivement sur des photos publicitaires où les montres affichent cette heure.
Laurent Daudet :
En effet, pour un LLM, une bouteille n’est qu’un mot. Il n’en comprend pas le sens tangible, physique. Les World Model cherchent à combler ce fossé. Cela peut inclure l’analyse de vidéos du monde réel pour faire progresser la robotique, par exemple.
Quant aux Frontier Model, ils représentent la pointe de la recherche autour des LLM. Ce sont les modèles les plus performants et les tentatives d’explorer d’autres architectures que les LLM classiques.

Description : Extrait de Dream Machine ou comment j’ai failli vendre mon âme à l’intelligence artificielle, scénario : Laurent Daudet, Appupen, dessin : Appupen, éditeur : Flammarion, 2023. © Flammarion.
Aujourd’hui, nous faisons face à une profusion de modèles d’IA ; de Hugging Face avec plus de 2 millions de modèles à la Chine qui en produit plusieurs milliers par mois. On peut se demander s’il y a un décalage entre les progrès technologiques et la réalité du déploiement en entreprise. Pouvez-vous nous en dire plus sur ce déploiement ?
Laurent Daudet :
Le déploiement de l’IA repose avant tout sur une philosophie qu’il faut bien comprendre. Nous n’avons pas besoin de modèles gigantesques à 500 milliards de paramètres pour répondre à la majorité des besoins en entreprise. Il existe un « sweet spot », autour de 40 à 50 milliards de paramètres, qui permet de couvrir la plupart des usages ciblés. Ces modèles peuvent être obtenus par distillation. C’est-à-dire que l’on entraîne un modèle plus petit à reproduire les performances d’un plus grand, ce qui permet de transférer ses compétences à moindre coût énergétique et opérationnel.
Mais la technologie seule ne suffit pas. Chez LightOn, nous avons constaté que les entreprises ont surtout besoin d’accompagnement. Dans des secteurs comme la banque, la santé ou l’assurance, les exigences en matière de confidentialité sont très fortes. Il faut donc travailler sur les processus de travail des salariés pour identifier ce qui peut réellement être optimisé ou automatisé, plutôt que d’ajouter un outil de plus. C’est pour cette raison que notre activité repose majoritairement sur le conseil, en complément des services techniques.
Clément Bénesse :
Les très grands modèles posent un véritable problème de changement d’échelle (scalabilité). Ils ne peuvent pas fonctionner en local sans infrastructures extrêmement puissantes, ce qui oblige à envoyer les données vers des serveurs externes. Cela soulève des enjeux majeurs de confidentialité, de sécurité et d’éthique. À l’inverse, des modèles trop petits manquent de capacités pour certaines tâches complexes. On en revient donc au compromis évoqué par Laurent, ce « sweet spot » qui permet de concilier performance et déploiement opérationnel. Par ailleurs, l’écosystème de l’IA repose largement sur une culture de l’« open model », avec des modèles dont les poids sont publics et téléchargeables, à la différence de solutions fermées comme ChatGPT, Claude ou Gemini. Le partage de ces modèles est peu coûteux et essentiel à la vitalité du secteur. Ils peuvent ensuite être adaptés aux besoins spécifiques des entreprises grâce au fine-tuning ou à la quantification.
Jordan Ricker :
Au-delà des considérations techniques, se pose la question de l’acceptabilité de l’IA dans les organisations. Cette acceptabilité varie fortement selon les secteurs et les publics. Dans le domaine de l’assurance, par exemple, l’erreur humaine accidentelle est souvent mieux tolérée que l’erreur aléatoire commise par une intelligence artificielle. Cela crée un décalage important dans la perception des outils.
Identifier des cas d’usage pertinents implique donc aussi de prendre en compte la réception sociale de l’IA, les attentes des utilisateurs finaux et leur niveau de confiance. Sans ce travail en amont, même des solutions techniquement performantes risquent de ne pas produire les bénéfices escomptés.
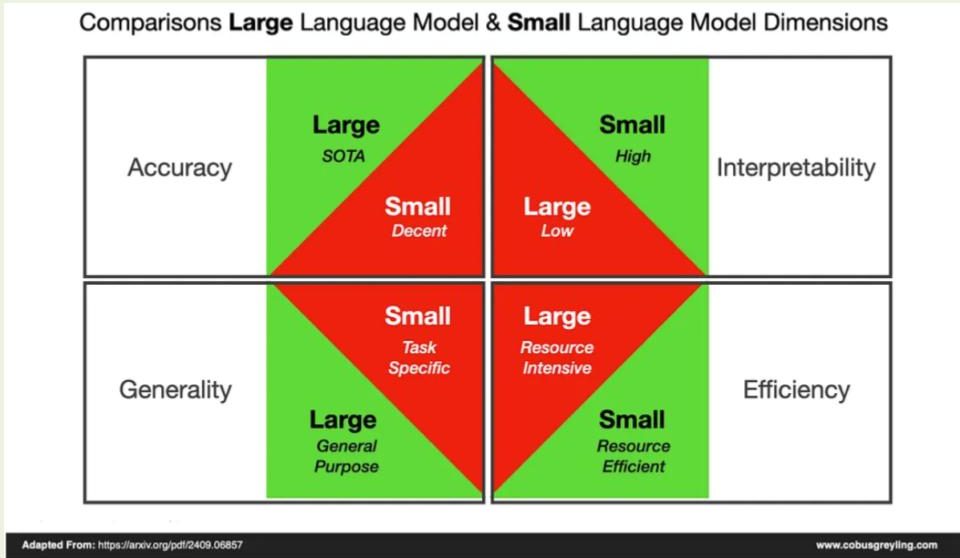
Description : Lihu Chen, Gaël Varoquaux, “What is the Role of Small Models in the LLM Era: A Survey”, https://arxiv.org/pdf/2409.06857
Le 2 décembre, Mistral a annoncé les modèles Ministral. Quelle est cette stratégie de décliner les grands modèles ?
Clément Bénesse :
L’idée est de mettre le bon modèle face à la bonne personne et à la bonne tâche. Une entreprise comme Mistral a besoin de réduire ses coûts d’inférence, notamment les coûts de la phase de « réflexion » du modèle, qui sont particulièrement élevés avec les nouveaux modèles produisant des chaînes de raisonnement. C’est une technique qui permet aux modèles de produire un contenu nettement plus pertinent. Pouvoir positionner un modèle de taille adaptée au bon endroit, c’est un vrai bonus économique.
De mon point de vue, OpenAI a pris coup sur coup en 2025. D’abord, les modèles open source chinois ont atteint un excellent niveau. Ensuite, Google dispose d’une quantité colossale de données et d’une interface que tout le monde connaît déjà, ce qui réduit la friction d’adoption. Avant, OpenAI pouvait se permettre plus de choses, comme l’idée d’introduire de la publicité. Aujourd’hui, la concurrence est bien plus féroce.
Jordan Ricker :
Il y a énormément de marketing lié au financement par le Venture Capital (capital risque) et à la bourse américaine. En réalité, on n’a pas besoin de modèles aussi lourds pour des tâches simples comme le formatage ou la synthèse de textes courts. Pour certaines applications critiques, par exemple un robot qui interagirait avec des enfants, on peut choisir de déployer un modèle très puissant qui intègre tous les scénarios de risque, ou bien simplement coder des interdictions strictes sans recourir au machine learning. On n’a pas besoin d’IA partout. Mais ça, ça ne séduit pas forcément les investisseurs.
Description : OpenAI’s new LLM exposes the secrets of how AI really works, MIT Technology Review, 13 novembre 2025, https://www.technologyreview.com/2025/11/13/1127914/openais-new-llm-exposes-the-secrets-of-how-ai-really-works/ (article payant)
Le 13 novembre 2025, OpenAI a dévoilé un modèle par « réseau clairsemé » qui permettrait de mieux découvrir le fonctionnement interne de l’IA. Où en est-on de cette compréhension ?
Clément Bénesse :
Le papier d’OpenAI est sans doute une opération de communication. On essaie de comprendre le fonctionnement interne des IA depuis 2018-2019. Il ne faut pas confondre l’explicabilité (quel neurone s’active pour quel concept) et l’interprétabilité (pourquoi le modèle donne cette réponse précise). De mon point de vue, la vraie finalité est de rassurer les utilisateurs et de leur faire mieux comprendre ce qui se passe.
Laurent Daudet :
La science en IA est en retard sur l’ingénierie. On arrive à construire des modèles extrêmement puissants, mais la recherche fondamentale peine à suivre. On ne sait pas forcément expliquer tous les comportements émergents, notamment les comportements « agentiques ». Les chercheurs commencent à comprendre comment cela fonctionne sur des modèles simplifiés. Je pense notamment à Lenka Zdeborová à l’EPFL, qui étudie comment les capacités augmentent avec la taille des modèles. Ils apprendraient d’abord le sens des mots, puis le contexte. Mais on reste sur des « modèles jouets ».
Jordan Ricker :
Les grands modèles fondation tels que ceux OpenAI restent des boîtes noires, l’opacité originelle étant celle des données d’entraînement, bien avant leur fonctionnement conversationnel. Il faut saluer les diverses initiatives européennes qui créent des modèles avec des données ouvertes, transparentes.

Description : Disrupting the first reported AI-orchestrated cyber espionage campaign, Anthropic, novembre 2025, https://www.anthropic.com/news/disrupting-AI-espionage
Le 23 novembre 2025, Anthropic a publié un rapport sur des hackers chinois qui auraient demandé à Claude un scénario de protection contre une cyberattaque, avant d’utiliser ce même plan pour une vraie attaque. Où en est-on de l’IA dans le cybercrime ?
Laurent Daudet :
Ce n’est pas une information anodine. Cela montre que de petites équipes sont désormais capables d’agir à des échelles auparavant impensables. L’IA permet de déceler les points faibles des systèmes et de lancer une quantité immense de tâches planifiées par des IA agentiques.
Jordan Ricker :
On observe une explosion capacitaire du côté de l’automatisation, mais aussi une chute des barrières à l’entrée pour des actions malveillantes. On assiste par ailleurs à une forme d’« artisanat du cybercrime », avec des individus isolés qui relaient des messages manipulatoires sans le savoir, parmi les contenus sensationnalistes qu’ils re-diffusent à grande échelle sur les plateformes pour en tirer profit…
Laurent Daudet :
On parlait de « vibe coding », c’est-à-dire coder uniquement grâce à l’IA sans vraiment connaître le code. On arrive presque au « vibe hacking ».
Estimez-vous que les LLMS vont ralentir au point d’atteindre un « mur », ou qu’ils vont au contraire continuer de progresser ?
Laurent Daudet :
On parle d’un mur comme on parlait de la fin du pétrole, mais on ne le voit pas encore. Les lois d’échelle continuent de fonctionner avec des modèles et des entraînements toujours plus gros. Ce phénomène s’est même démultiplié puisque l’on scale maintenant le pré-entraînement et le post-entraînement. Le pré-entraînement porte sur des données brutes, le post-entraînement sur des tâches spécifiques. On scale aussi l’inférence (le temps de réflexion du modèle avant qu’il réponde à l’utilisateur), avec des dizaines voire des centaines d’appels au LLM pour les IA agentiques. Le scaling a encore de beaux jours devant lui.
Clément Bénesse :
Il y a la question du compute, puisque l’on arrive à de très grosses architectures comme pour les data center, avec de fortes contraintes énergétiques et économiques. Mais plusieurs facteurs permettent de continuer à progresser, comme les données de meilleure qualité en post-training. C’est ce que l’on injecte à la toute fin de l’entraînement et qui a un impact majeur sur la qualité finale, comme l’ont montré les travaux de DeepSeek.
L’architecture « Mixture of Experts » permet aussi d’avoir des réponses plus précises sur certains sujets à moindre coût total. Je suis assez optimiste, car on réalise que l’on peut utiliser l’IA dans un vaste arsenal d’outils combinés.
Sur le même sujet
-
Événement

Quelle gouvernance pour une intelligence artificielle responsable ?
Jeudi 13 novembre, de 9h à 20h
Campus Fonderie de l'Image / L'Ecole Multimédia, 83 avenue Gallieni, 93170 Bagnolet

